
3.3 Transfer Learning
Deep learning에는 많은 양의 데이터셋이 필요하다. 그럴 시간도 돈도 없다면 어떻게 하지?
Transfer Learning(전이 학습)이란 큰 데이터셋으로 미리 훈련된 모델의 가중치를 가져와 우리가 쓰고자 하는 곳에 맞게 보정해서 사용하는 것을 의미한다. 이때 미리 훈련된 모델을 network라고 한다.
이로부터 비교적 적은 dataset으로도 문제를 해결할 수 있게 된다.
3.3.1 Feature Extractor
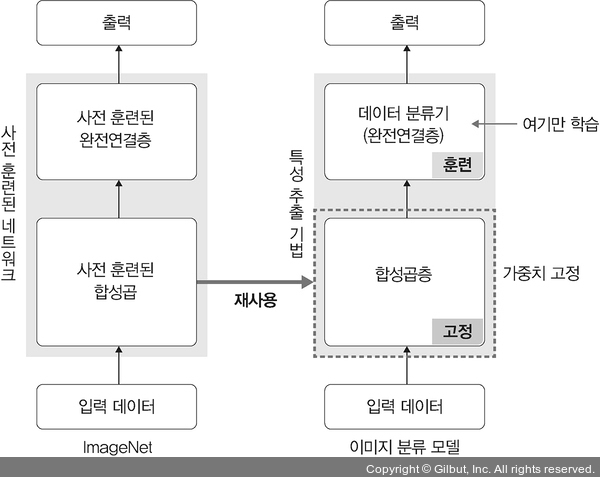
Feature Extractor(특성 추출)이란 사전 훈련된 model을 가져와 마지막 fully connected layer만 새로 만드는 기법을 말한다.
즉, 학습할 때에는 마지막, category를 결정하는 부분만을 학습하고 나머지 layer들은 학습되지 않도록 하는 것이다.
이미지 분류의 예시를 들자. Feature extractor는 다음 두 부분으로 구성된다.
- Convolutional Layer : convolutional layer 및 pooling layer로 구성.
- Data Classifier(Fully Connected Layer) : 추출된 feature를 입력받아 image에 대한 class를 분류하는 부분.
사전 훈련된 network의 convolutional layer(가중치는 고정되어 있다.)에 새 data를 통과시켜, 그 output을 classifier에서 훈련시키는 것!
사전 훈련된 model은 다음과 같은 것들을 사용한다.
- ImageNet
- Xception
- Inception V3
- ResNet 50
예시를 보이기 전 필요한 라이브러리 설치.
pip install opencv-python
Line 5 : OpenCV 라이브러리
Line 9 : Computer vision을 위한 패키지
Line 10 : 데이터 전처리를 위한 패키지
Line 11 : pytorch network 사용을 위한 패키지
다음은 전처리 방법을 정의하는 코드이다.
Line 3~9 : torchvision.transform은 이미지 데이터를 변환해 newtork의 input으로 사용할 수 있도록 변환한다. Parameter들은 다음과 같다.
- Resize : 이미지의 크기 조정
- RandomResizedCrop : 이미지를 랜덤한 비율로 자른 후 데이터 크기를 조정해 데이터를 확장하는 역할을 한다. 이에 반해 Resize는 convolution layer 통과를 위해 이미지 크기를 조정한다.
- RandomHorizontalFlip : 이미지를 랜덤하게 수평으로 뒤집는다.
- ToTensor : 이미지 데이터를 텐서로 변환한다.
Line 10~13 : data.ImageFolder는 데이터로더가 불러올 데이터와 방법을 정의한다.
- data_path : 데이터가 위치한 경로
- transform : 이미지 데이터 전처리
Line 14~19 : DataLoader는 데이터를 불러오는 부분으로, Line 10에서 정의한 ImageFolder(train_dataset)을 데이터로더에 할당한다.
- train_dataset : 데이터셋 지정
- batch_size : 한 번에 불러올 데이터양 결정
- num_workers : 데이터를 불러올 때 사용할 하위 프로세스 개수
- shuffle : 데이터를 무작위로 섞을 것인가?
---
Result :
385
불러 온 이미지를 출력해 보자.
Line 3 : iterator 사용. next()는 iterator가 다음에 출력해야 할 요소를 반환한다. 따라서 train_loader의 iterator를 next()에 전달해 차례로 꺼낼 수 있게 된다.
Line 4 : 개와 고양이에 대한 class
Line 8 : label 정보를 함께 출력

자. 데이터는 준비되었다. 이제 pre-trained network가 필요하다. ResNet18을 사용하자.
Line 1 : pretrained=True는 사전 학습된 가중치를 사용하겠다는 것. 아무 parameter도 넣지 않으면 무작위 가중치의 모델을 구성한다.
이렇게 내려받은 Resnet18의 convolutional layer는 사용하되 parameter 학습은 진행하지 않을 것이다.
Line 4 : model 일부(convolutional & pooling layer)를 고정하고, backpropagation 중 parameter의 변화를 계산하지 않는다!
가져온 ResNet18에 fully connected layer를 추가할 것이다. 여기서는 개와 고양이를 분류하는 용도로 쓰이게 될 것이다.
Line 1 : 512는 input size, 2는 class가 2개라는 의미.
Line 3 : model.named_parameters()는 model에 접근해 paramater 값을 가져온다.
---
Result :
fc.weight tensor([[-0.0369, -0.0269, 0.0250, ..., -0.0207, -0.0211, 0.0205],
[ 0.0109, 0.0036, -0.0236, ..., -0.0307, -0.0291, 0.0429]])
fc.bias tensor([ 0.0136, -0.0417])
학습 준비를 시작하자. Model 객체 생성 후 cost function을 정의한다.
Line 1 : model 객체 생성
Line 3~4 : Convolutional layer의 weight 고정
Line 7~8 : fully connected layer는 학습시킬 것.
Line 10~11 : optimizer와 cost function 정의.
---
Result :
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=2, bias=True)
)
Resnet18 모델 마지막에 fully connected layer가 추가되어 있는 것을 확인할 수 있다.
Training을 위한 함수를 만들자.
Line 2 : PC의 현재 시간
Line 7 : epoch만큼 반복할 것.
Line 14 : DataLoader에 전달된 데이터만큼 반복할 것.
Line 19 : 기울기는 0으로 설정.
Line 20 : Feedforward 학습.
Line 22 : torch.max()는 tensor와 dim을 입력으로 받아, 해당 dim에 존재하는 tensor 열의 최댓값과 해당 최댓값이 위치하는 index를 반환한다. preds는 index를 가져온 것.
Line 23 : Backpropagation 학습.
Line 26 : 출력 결과와 label의 오차를 계산한 결과를 누적해서 저장한다.
Line 27 : 출력 결과와 label이 동일한지 확읺나 결과를 누적해서 저장한다.
Line 29~30 : 평균 오차와 평균 정확도를 계산한다.
Line 39 : 모델 재사용을 위해 저장.
Line 42 : 학습 시간을 계산.
Line 45 : 모델 정확도와 오차를 반환.
Fully connected layer는 학습을 하도록 설정한 것을 잊지 말자. 학습을 통해 얻은 parameter를 optimizer에 전달해야 한다.
Line 4 : parameter(weight, bias) 학습 결과를 저장.
Line 7 : 학습 결과를 optimizer에 전달
이제 모델을 학습시킬 때가 됐다! 전달되는 parameter는 (모델, 학습 데이터, cost function, optimizer, 장치(CPU 또는 GPU))이다.
Result :
Epoch 0/12
----------
Loss: 0.4818 Acc: 0.8000
Epoch 1/12
----------
Loss: 0.3400 Acc: 0.8727
Epoch 2/12
----------
Loss: 0.2794 Acc: 0.8987
Epoch 3/12
----------
Loss: 0.3011 Acc: 0.8701
Epoch 4/12
----------
Loss: 0.2130 Acc: 0.9506
Epoch 5/12
----------
Loss: 0.2144 Acc: 0.9325
Epoch 6/12
----------
Loss: 0.2134 Acc: 0.9169
Epoch 7/12
----------
Loss: 0.2516 Acc: 0.8987
Epoch 8/12
----------
Loss: 0.2024 Acc: 0.9143
Epoch 9/12
----------
Loss: 0.2301 Acc: 0.9013
Epoch 10/12
----------
Loss: 0.2948 Acc: 0.8597
Epoch 11/12
----------
Loss: 0.1838 Acc: 0.9299
Epoch 12/12
----------
Loss: 0.2123 Acc: 0.8987
Training complete in 0m 56s
Best Acc: 0.950649
정확도는 95.1%. 쓸만하다. Training에 쓰인 파일들은 저장해 두었으니 언제든 꺼내서 쓸 수 있다.
자, 이제 test용 데이터를 꺼내 와서 model의 정확도를 평가할 시간이다.
Test용 데이터를 불러와 전처리를 진행한다.
평가를 위한 함수를 정의한다.
Line 5 : device가 "cuda", "cpu"가 섞여 있을 수 있으니 하나로 통일시킨다.
Line 7 : glob()은 현재 디렉토리에서 원하는 파일만 추출해서 가져올 때 사용한다. pth 확장자를 갖는 파일은 train data로 model을 훈련시킬 때 생성되었던 파일.
Line 23 : torch.no_grad()는 autograd를 사용하지 않겠다는 의미.
Line 24 : 데이터를 모델에 적용한 결과를 outputs에 저장한다.
Line 26 : torch.max는 주어진 tensor 배열에서 최댓값의 index를 반환.
Line 27~28 : torch.max로 출력된 값이 0.5보다 크면 올바르게 예측, 작으면 틀리게 예측.
Line 28 : preds 배열과 labels가 일치하는가? 일치하는 것들의 개수 합을 출력.
Test 데이터의 정확도를 출력하자.
Result :
saved_model ['../DL/Ch 3/3.3/data/catanddog\\00.pth', '../DL/Ch 3/3.3/data/catanddog\\01.pth', '../DL/Ch 3/3.3/data/catanddog\\02.pth', '../DL/Ch 3/3.3/data/catanddog\\03.pth', '../DL/Ch 3/3.3/data/catanddog\\04.pth', '../DL/Ch 3/3.3/data/catanddog\\05.pth', '../DL/Ch 3/3.3/data/catanddog\\06.pth', '../DL/Ch 3/3.3/data/catanddog\\07.pth', '../DL/Ch 3/3.3/data/catanddog\\08.pth', '../DL/Ch 3/3.3/data/catanddog\\09.pth', '../DL/Ch 3/3.3/data/catanddog\\10.pth', '../DL/Ch 3/3.3/data/catanddog\\11.pth', '../DL/Ch 3/3.3/data/catanddog\\12.pth']
Loading model ../DL/Ch 3/3.3/data/catanddog\00.pth
Acc: 0.9082
Loading model ../DL/Ch 3/3.3/data/catanddog\01.pth
Acc: 0.8980
Loading model ../DL/Ch 3/3.3/data/catanddog\02.pth
Acc: 0.9184
Loading model ../DL/Ch 3/3.3/data/catanddog\03.pth
Acc: 0.9388
Loading model ../DL/Ch 3/3.3/data/catanddog\04.pth
Acc: 0.9388
Loading model ../DL/Ch 3/3.3/data/catanddog\05.pth
Acc: 0.9082
Loading model ../DL/Ch 3/3.3/data/catanddog\06.pth
Acc: 0.9388
Loading model ../DL/Ch 3/3.3/data/catanddog\07.pth
Acc: 0.9184
Loading model ../DL/Ch 3/3.3/data/catanddog\08.pth
Acc: 0.9388
Loading model ../DL/Ch 3/3.3/data/catanddog\09.pth
Acc: 0.9286
Loading model ../DL/Ch 3/3.3/data/catanddog\10.pth
Acc: 0.9388
Loading model ../DL/Ch 3/3.3/data/catanddog\11.pth
Acc: 0.9286
Loading model ../DL/Ch 3/3.3/data/catanddog\12.pth
Acc: 0.9388
Validation complete in 0m 42s
Best Acc: 0.938776
테스트 정확도 역시 94%로 높은 정확도를 보였다. Network를 직접 구현하고 parameter를 최적화시키려고 했다면 훨씬 오랜 시간이 걸렸을 것이다.
학습 결과를 시각적으로 보고 싶다면 다음과 같이.
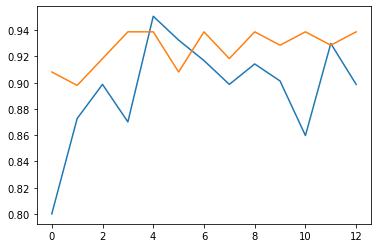
Training data와 test data에 대해 epoch가 진행될 때마다 정확도를 출력한 것이다. 둘 다 epoch가 진행될수록 정확도가 높아져 100%에 가까워짐을 확인할 수 있다.
이번에는 오차 정보를 확인하자.
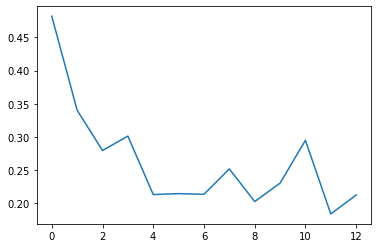
Training data에 대해 epoch가 진행될 때마다 오차를 출력한 결과이다. Epoch가 진행될수록 오차는 낮아진다.
실제로 데이터를 잘 예측하는지 확인하고 싶다. 예측된 이미지 출력을 위한 전처리 함수를 만들자.
Line 2 : tensor.clone()은 기존 텐서를 복사해 생성. detach()는 기존 텐서에서 기울기가 전파되지 않는 텐서이다. 즉 기존 텐서를 복사하되 기울기에 영향을 주지는 않겠다는 뜻.
Line 5 : clipping. image 데이터를 0과 1 사이로 제한한다.
| 구분 | 메모리 | 계산 그래프 상주 유무 |
|---|---|---|
tensor.clone() |
새롭게 할당 | 계산 그래프에 계속 상주 |
tensor.detach() |
공유해서 사용 | 계산 그래프에 상주하지 않음 |
tensor.clone().detach() |
새롭게 할당 | 계산 그래프에 상주하지 않음 |
Test data를 가져와 개와 고양이를 실제로 잘 분류하는지 확인하자.
Line 2~3 : test dataset의 iterator를 정의. image와 label을 분리해서 가져온다.
Line 10 : add_subplot으로 여러 image를 출력.
- 1st param. : 행의 수
- 2nd param. : 열의 수
- 3rd param. : index
- 4th param. : tick의 여부.
Line 12 : classes[preds[idx].item()]은 preds[idx].item() 값이 classes로 정의된 '0'과 '1' 중 어떤 값을 갖는지 판별하겠다는 의미이다. 즉 이 값이 0이면 고양이, 1이면 개를 출력한다.
이때 텍스트 색이 초록색이면 정확히 예측한 것, 빨간색이면 잘못 예측한 것을 의미하게 된다.

3.3.2 Fine-Tuning
Fine-tuning(미세 조정) 기법은 feature extractor에서 더 나아가 pre-trained model과 convolutional layer, data classifier의 가중치를 업데이트하면서 훈련시킨다.
Feature extractor는 목표의 feature를 잘 추출했다는 전제 하에 좋은 성능이 나오기 때문에, feature가 잘못 추출되었다면 fine-tuning을 사용해 새로운 image data를 사용해 가중치를 업데이트하고, feature를 다시 추출할 수 있다.
즉, pre-trained model 또는 weight의 일부를 목적에 맞게 재학습시키는 것!
이 과정에서 연산량이 많기 때문에, CPU보다는 GPU 연산을 사용하는 것을 추천한다.
| 데이터셋이 크고 사전 훈련된 모델과 유사성이 작은 경우 | 모델 전체를 재학습 |
| 데이터셋이 크고 사전 훈련된 모델과 유사성이 큰 경우 | convolutional layer의 뒷부분(fully connected layer와 가까운 부분)과 data classifier(fully connected layer)를 재학습 |
| 데이터셋이 작고 사전 훈련된 모델과 유사성이 작은 경우 | convolutional layer의 일부분과 data classifier를 재학습. 데이터가 적으므로 fine-tuning의 효과가 없을 수 있다. |
| 데이터셋이 작고 사전 훈련된 모델과 유사성이 큰 경우 | data classifier만 재학습. 데이터가 적으므로 많은 layer에 fine-tuning을 적용하면 overfitting의 위험이 있다. |
-
뭔가 애매한 사진들도 섞여있긴 하지만... ↩