3.1 Convolutional Neural Network
Deep learning의 feedforward 과정 이후에는 error가 output layer에서 hidden layer, input layer로 전달된다. 계산이 더럽게 오래 걸리고 메모리도 엄청 쓴다. 특히 이미지와 같이 한 장당 수백만 개의 픽셀 정보가 있는 dataset같은 경우 더더욱!
CNN(Convolutional Neural Network)은 이미지 전체를 한 번에 계산하지 않고 국소적인 부분만 계산해서 시간과 메모리를 절약한다.
3.1.1 Flattening

이미지를 분석할 때는 왼쪽과 같은 배열을 오른쪽처럼 펼친 뒤, weight를 곱해 hidden layer로 전달한다.
문제는 이 경우 이미지가 가지고 있는 공간적인 구조가 망가지게 되는데, 이처럼 다차원 배열 데이터의 구조가 망가지는 것을 방지하기 위해 CNN에 도입하는 것이 바로 convolutional layer이다.
3.1.2 Structure of CNN
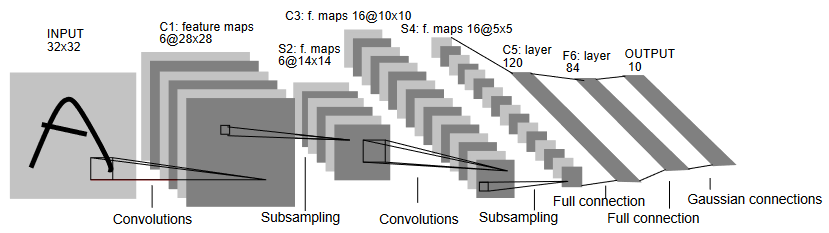
CNN은 다음 다섯 층으로 구성된다.
Input Layer
Input image data는 input layer로 들어온다. 여기서 image는 height, width, channel의 3-dim. data이다. Channel은 grayscale image의 경우 1, RGB image의 경우 3의 값을 갖는다.
Convolutional Layer
Convolutional Layer는 input data로부터 feature를 추출한다. 여기서 feature 추출에는 kernel 또는 filter가 사용된다. 이들은 image 전체를 스캔하면서 일부 feature를 뽑아낸다. 그 결과를 feature map이라고 부른다.
Kernel은 $3 \times 3$, $5 \times 5$ 크기를 주로 쓰며, 일정 간격(stride)을 따라 이동하며 image의 feature를 계산한다.

Feature 계산은 위와 같다. Kernel과 크기가 같은 input image의 일부분 배열과 kernel의 weighted sum을 구한다. 대응되는 위치의 숫자끼리 곱해서 더하면 된다.
Stride가 1인 경우, input array 전체를 순회하면 다음 feature map이 생성된다.

Convolutional layer를 거치면서 기존의 (6, 6, 1)짜리 image가 (4, 4, 1)짜리 feature map으로 줄어들었다.
위 예시는 grayscale 이미지였고, 다음은 RGB의 예시이다. RGB의 channel은 3이므로 filter 역시 3 channel이어야 한다.2
RGB 각각에 서로 다른 weighted sum을 취해서 결과를 더해주면 된다. 아래를 보자.

두 개 이상의 filter를 적용한 convolution도 생각해 볼 수 있다. 이 경우 filter를 거친 각각의 feature map이 하나의 channel이 된다.

Output의 크기를 input 크기와 똑같이 하고 싶으면 어떻게 할까?
더 큰 input에 convolution을 취하는 척 하면 된다. Grayscale의 예시와 같이 $6 \times 6$ 크기의 input image에 $3 \times 3$ kernel을 취한다고 해보자. Input image 주위에 가상의 원소가 존재한다고 가정하고 $8 \times 8$ 크기로 부풀린 다음에 convolution을 취하면,

자, 이렇게 output이 똑같이 $6 \times 6$ 크기로 나온다. 이렇게 input array 주위를 가상의 원소로 채우는 작업을 padding이라고 한다. Padding 과정에서 가상의 값은 모두 0으로 채운다.
즉, 계산값에 영향을 미치지 않고 input data의 크기를 유지시키고 싶을 때 사용한다.
Convolutional layer를 정리하면,
- Input data : $W_1 \times H_1 \times D_1$
- Hyperparameters
- Num. of Kernel : $K$
- Size of Kernel : $F$
- Stride : $S$
- Padding : $P$
- Output data
- $W_2 = (W_1-F+2P)/S+1$
- $H_2 = (H_1-F+2P)/S+1$
- $D_2 = K$
Pooling Layer
Pooling layer 또는 subsampling layer에서는 convolutional layer와 비슷하게 feature map의 차원을 낮춰 연산량을 감소시킨다.
주요한 feature만을 추출하기 위해 다음 두 연산 중 하나를 사용한다.
- Max pooling : 대상 영역에서 최댓값만 추출
- Average pooling : 대상 영역의 평균값을 반환
대부분의 CNN에서는 max pooling을 주로 사용.
간단하다. Filter 크기만큼의 영역에서 최댓값을 선택해 반환하면 된다.

Pooling layer를 정리하면,
- Input data : $W_1 \times H_1 \times D_1$
- Hyperparameters
- Size of Kernel : $F$
- Stride : $S$
- Output data
- $W_2 = (W_1-F)/S+1$
- $H_2 = (H_1-F)/S+1$
- $D_2 = D_1$
Fully Connected Layer
Dim.이 줄어든 feature map은 fully connected layer로 이동한다. 여기서 image는 3-dim. vector에서 1-dim. vector로 펼쳐져셔 들어가게 된다.
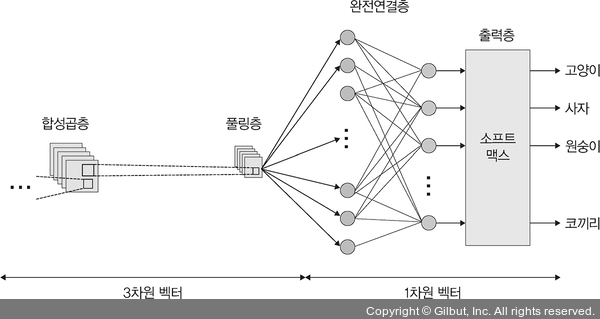
Output Layer
Output layer에는 softmax function이 사용된다. Image가 각 label에 속할 확률값을 출력하여 가장 높은 확률값의 label이 최종 image 분류 결과가 되는 것이다.
3.1.3 1D, 2D, 3D Convolution
1D Convolution
Filter가 시간을 축으로 좌우로만 이동한다면 1D convolution이라고 한다. Input ($W$)과 filter ($k$)에 대한 출력은 $W$가 된다.
예를 들어 input이 $[1, 1, 1, 1, 1]$이고 filter가 $[0.25, 0.1, 0.15]$이면 output은 $[0.5, 0.5, 0.5]$가 된다.
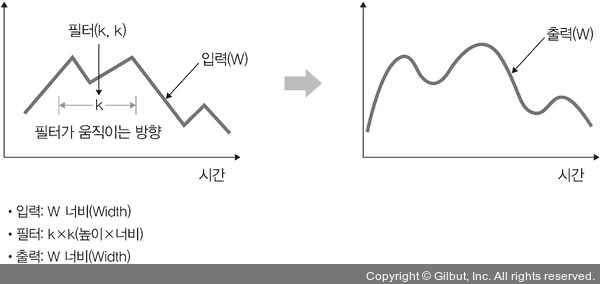
1D convolution은 곡선 완화에 주로 사용된다.
2D Convolution
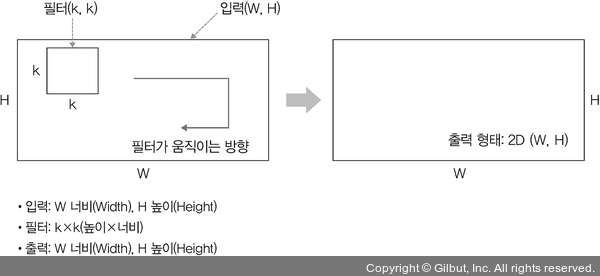
Filter가 두 방향으로 이동한다면 2D convolution이라고 한다. Input ($W, H$)과 filter ($k, k$)에 대한 출력은 2D 배열이 된다.
3D Convolution
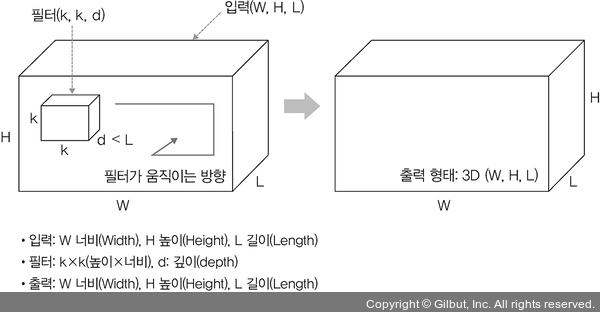
Filter가 세 방향으로 이동한다면 3D convolution이라고 한다. Input ($W, H, L$)과 filter ($k, k, d$)에 대한 출력은 3D 배열이 된다. 이때 $d$는 $L$보다 작아야 한다.
2D Convolution with 3D Input
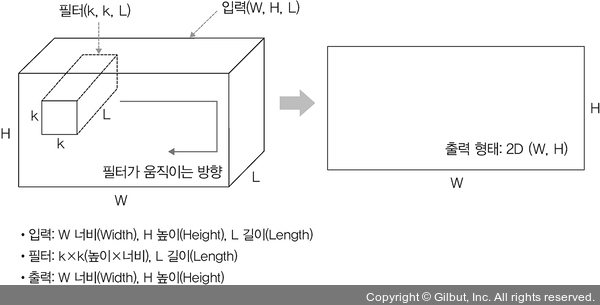
Input이 3D이면서 output이 2D가 되게 할 수 있다. Filter의 길이 $d$를 input의 길이 $L$과 같게 하면 된다. Input ($W, H, L$)과 filter ($k, k, L$)에 대한 출력은 2D 배열이 된다. 이때 filter는 두 방향으로만 움직인다.
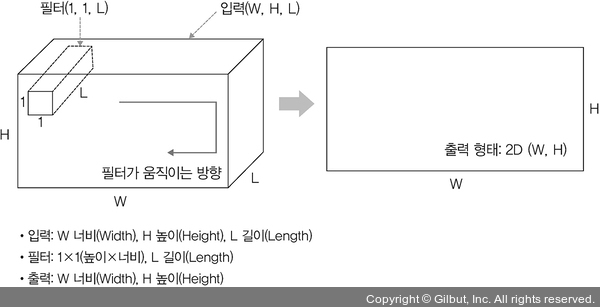
1$\times$1 Convolution
Input ($W, H, L$)과 filter ($1, 1, L$)에 대한 출력은 2D 배열이 된다. 이는 channel 수를 조정해서 연산량을 감소시킬 때 쓰인다.