2.1 Neural Network
Perceptron을 여러 겹으로 겹치면 복잡한 함수도 표현할 수 있었다.
XOR gate를 구현하기 위해서는 AND, NAND, OR gate가 필요했고, 이들을 구현하기 위해 적절한 weight, bias를 직접 설정해 주었다. 이제 데이터를 통해 weight와 bias를 적절한 값으로 학습해 보자.
2.1.1 Neural Network
Neural network(NN)를 그림으로 나타내면 다음과 같다.

가장 왼쪽 줄이 input layer, 맨 오른쪽 줄이 output layer, 중간 줄이 hidden layer이다.
아직까지는 multi-layer perceptron과 크게 다르지 않다.
Perceptron을 다시 되돌아보면, input $x_1$, $x_2$를 받아 $y$를 출력하는 perceptron은 다음과 같았다.

위 그림에는 bias가 나타나있지 않다. Network에 bias를 명시하자.

식을 더 간단히 하자. Activation function $h(x)$를 도입하자. $h(x)$는 input 신호의 총합이 활성화를 일으키는지를 확인한다.
\[a = b+w_1x_1+w_2x_2 \\ y = h(a)\\ h(x)=\begin{cases} 0 & (x \leq 0) \\ 1 & (x > 0) \end{cases}\]다음은 Activation function까지 명시한 NN의 그림이다.

2.1.2 Activation Function
Step Function
위 예시와 같은 함수를 step function이라고 한다. 0을 경계로 출력이 0에서 1로 바로 뛴다.

Sigmoid Function
우리에게 익숙한 sigmoid function을 다시 소개.
\[\sigma(x) = \frac{1}{1+e^{-x}}\]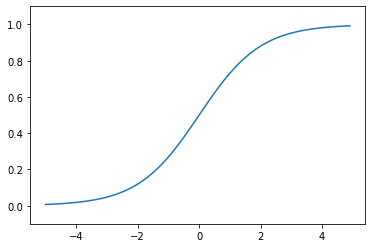
Step function과 sigmoid function은 nonlinear function이다. NN에서는 반드시 nonlinear만을 activation function으로 사용한다. 층이 깊어지면 activation function이 계속해서 합성되는데, linear function은 합성시켜도 linear function이므로 하나의 층으로 대체될 수 있기 때문이다.
Multi-layer를 구현하기 위해서는 nonlinear function을 사용할 것.
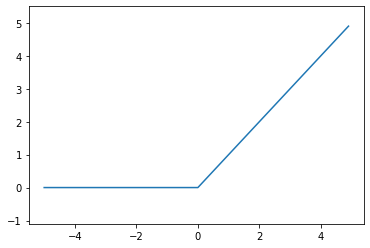
ReLU Function
ReLU(Rectified Linear Unit) function은 input이 0을 넘으면 그대로 출력하고, 0 이하이면 0을 출력한다.
\[h(x)=\begin{cases} 0 & (x \leq 0) \\ x & (x > 0) \end{cases}\]