
1.1 Perceptron
지금부터가 딥러닝의 시작.
1957년, Frank Rosenblatt가 뉴런을 모방해서 개발한 알고리즘이 perceptron이다. Perceptron은 여러 개의 신호를 받아서 하나의 신호를 출력한다.
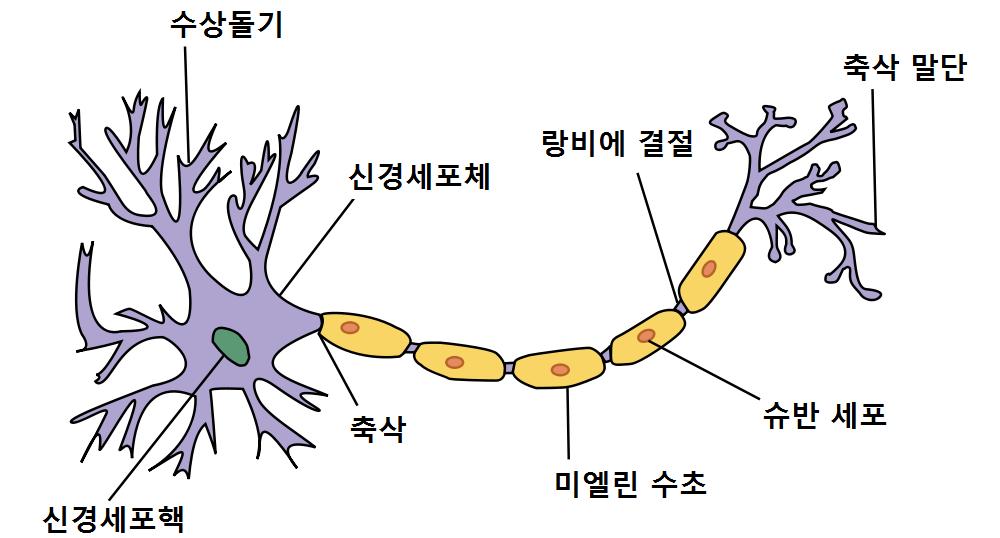
실제 뉴런은 다수의 input을 수상돌기로부터 받아 신경세포 내에서 이들을 하나의 신호로 통합. 통합된 신호값이 일정 threshold를 넘어가면 축삭돌기로 하나의 output을 전송한다. threshold 미만의 신호는 전송하지 않는다.
Perceptron은 여러 개의 input 신호를 linear combination을 이용해 하나의 값으로 통합. 임계치를 초과하는지 여부를 activation function을 통해 판단하고 초과하면 1, 아니면 0을 출력한다.

위 예시는 입력으로 2개의 신호를 받는 perceptron. $x_1$, $x_2$가 input, $y$는 output, $w_1$, $w_2$는 weight이다. Input node의 신호가 뉴런에 보내질 떄 각각 weight가 곱해진다. 이 신호의 총합이 임계치 $\theta$를 넘어가면 1을 출력한다.
\[y = \begin{cases} 0 & (w_1x_1+w_2x_2 \leq \theta) \\ 1 & (w_1x_1+w_2x_2 > \theta) \end{cases}\]1.1.1 AND Gate
AND gate의 진리표.
| $x_1$ | $x_2$ | $y$ |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 1 | 1 |
이 AND gate를 perceptron으로 표현해 보자. 진리표와 같은 값을 갖도록 하는 $w_1$, $w_2$, $\theta$는 무엇이 될까?

Linear regression의 경우를 떠올려 보면 위처럼 0과 1로 영역을 나누는 직선 $w_1x_1+w_2x_2 = \theta$를 생각하면 될 것이다. 이를 만족시키는 조합은 무수히 많으며, $(0.5, 0.5, 0,6)$ 등이 있을 것이다.
이를 파이썬으로 구현해 보자.
Weight와 bias를 도입해서 코드를 다시 쓰자. $\theta$를 $-b$로 대체하고 식을 정리하자.
array 사이의 곱 *는 성분별 곱임에 유의. mul() 함수를 써도 무방.
같은 방법으로 NAND, OR Gate 등도 구현할 수 있다.
이것으로 우리는 뉴런과 비슷한 역할을 하는 알고리즘을 구현해 냈다. 이걸 사용하면 사람처럼 사고하는 인공지능도 뚝딱 만들어지는 게 아닐까?
1.1.2 XOR Gate
그러나 Minsky, Papert(1969)는 perceptron이 XOR 문제를 학습하지 못한다는 걸 알아냈다. XOR gate의 진리표부터 보자.
| $x_1$ | $x_2$ | $y$ |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 0 |
XOR gate는 $x_1$과 $x_2$ 중 하나가 1일 때만 1을 출력한다. 이를 perceptron으로 구현하기 위해선 어떻게 weight와 bias를 설정해야 할까?

0과 1을 분류해낼 수 있는 직선을 생각해야 하는데… 직선 하나로는 불가능하다!