
1.4 Word Embedding
이번 내용에는 Text Analytics Toolbox™ Model for fastText English 16 Billion Token Word Embedding 패키지 설치가 필요하다.
1.4.1 Word Embedding
사전에 훈련된 word embedding을 fastTextWordEmbedding을 사용해 불러온다.
emb = fastTextWordEmbedding

Word embedding이란 단어를 숫자 혹은 벡터로 표현하는 것. 이렇게 하면 단어끼리의 관계를 숫자로 표현할 수 있고 단어 사이의 연산도 가능하게 된다.
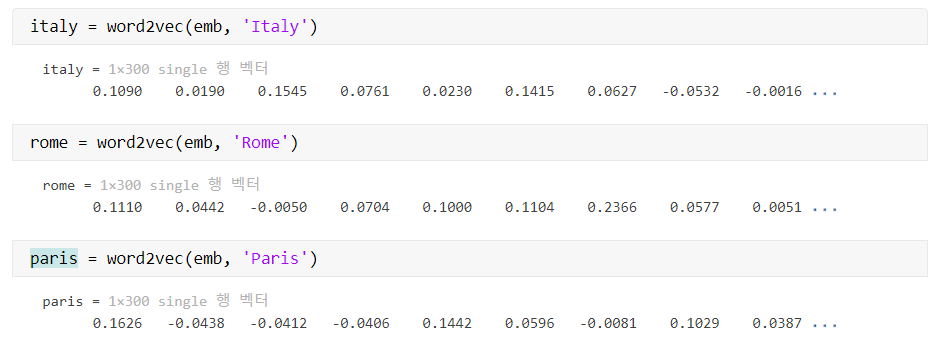
word2vec을 사용해 단어를 벡터에 mapping하자.
% 단어를 embedding
italy = word2vec(emb, 'Italy')
rome = word2vec(emb, 'Rome')
paris = word2vec(emb, 'Paris')
이제 다음과 같은 질문을 생각하자.
\[\textrm{Italy - Rome + Paris = ?}\]word = vec2word(emb, italy - rome + paris)
---
word = "France"
