
1.3 Text Data Analysis
1.3.1 Open Data
Matlab의 라이브 편집기에서 분석할 파일을 열어보자. 작업공간에 해당 파일이 있어야 한다.
open paper.pdf
본 예시에는 2012년 4월 1일에 arXiv에 submit된 Daniel Schoch의 논문 ‘Gods as Topological Invariants’를 사용했다.1

1.3.2 Access and Explore Text Data
해당 문서에 접근해 필요한 데이터를 받아오자.
% 문서 전체 내용을 가져오고 싶으면
mypdf = extractFileText('paper.pdf')
% 그 안에서 특정 문자 사이의 내용만을 가져오고 싶으면
mypdf = extractBetween(mypdf, 'Abstract', 'References')
---
mypdf =
"GODS AS TOPOLOGICAL INVARIANTS
DANIEL SCHOCH
Abstract. We show that the number of gods in a universe must equal the
Euler characteristics of its underlying manifold. By incorporating...
1.3.3 Clean Up Text
그런데 이 mydef 변수는 $1 \times 1$짜리 string이다.

이를 정리할 필요가 있다. 먼저 문장 단위로 끊어보자.
t = split(mypdf, '.')

기호를 전부 지워준다. regexprep(str,expression,replace)은 str에서 expression과 일치하는 텍스트를 replace로 바꾸어 준다.
t = regexprep(t, '[^A-Za-z0-9\'']', ' ')
문장 단위의 데이터를 단어로 쪼개는 과정(tokenization)을 거친다.
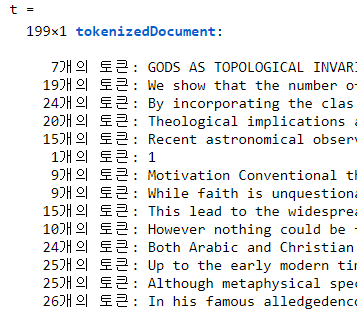
t = tokenizedDocument(t)
분석의 정확도를 높이기 위해 전부 소문자로 바꾼다.
t = lower(t)
관사, 전치사와 같은 의미와 관련없는 단어들(‘a’, ‘an’’, ‘with’, ‘from’ 등)을 지운다.
t = removeWords(t, stopWords)

글자 수가 적은 단어들을 지운다.
t = removeShortWords(t, 3)

Bag-of-words 모델과 Word Cloud Chart
bagOfWords는 텍스트를 단어가 문장에서 등장하는 횟수를 기록한다.
wordcloud를 이용하면 이에 따른 워드 클라우드 차트를 보여준다.
b = bagOfWords(t);
wordcloud(b)

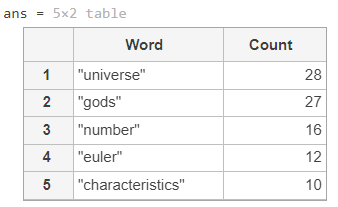
빈도수가 높은 단어들이 하이라이트되어 나타나는 것을 볼 수 있다. topkwords 함수를 쓰면 빈도가 높은 순으로 표를 만들어서 볼 수 있다.
topkwords(b, 5)
그런데, 주요 키워드는 반드시 한 단어로만 나타나지 않는다. Manifold보다 topological manifold가 더 중요할 수 있고, machine보다 machine learning이 더 중요할 수도 있다. 인접한 단어들까지 판단하는 것이 좋겠다.
Bag-of-n-grams 모델은 각 n-gram(연속된 n개 단어로 이루어진 구문)이 문서에서 나타나는 횟수를 기록한다.
bg = bagOfNgrams(t, 'NgramLengths', 2);
wordcloud(bg)
topkngrams(bg, 5)

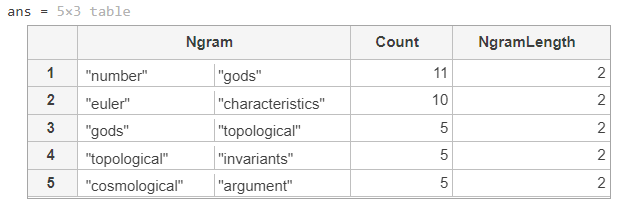
두 단어로 이루어진 키워드가 등장하는 빈도 수가 나타난다.2